Table of Contents
Data Compression
Data Compression shrinks down a file so that it takes up less space. This is desirable for data storage and data communication. Storage space on disks is expensive so a file which occupies less disk space is “cheaper” than an uncompressed file. Smaller files are also desirable for data communication because the smaller a file the faster it can be transferred. A compressed file appears to increase the speed of data transfer over an uncompressed file.
In his 1948 paper, “A Mathematical Theory of Communication,” Claude E. Shannon formulated the theory of data compression.

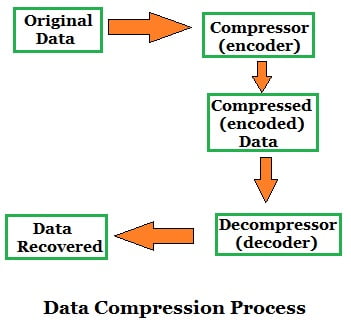
In computer science and information theory, data compression or source coding is the process of encoding information using fewer bits (or other information-bearing units) than an unencoded representation would use through the use of specific encoding schemes. One popular instance of compression with which many computer users are familiar is the ZIP file format, which, as well as providing compression, acts as an archiver, storing many source files in a single destination output file.
As with any communication, compressed data communication only works when both the sender and receiver of the information understand the encoding scheme. For example, this text makes sense only if the receiver understands that it is intended to be interpreted as characters representing the English language. Similarly, compressed data can only be understood if the decoding method is known by the receiver.
Data compression is commonly used in PSTN (Public Switched Telephone Network). Call charges in PSTN are based upon duration and distance. If it is possible to reduce the transmission duration for a data block, it can reduce the call charges and also increase the transmission rates.
Types of Data Compression
There are two main types of this technique:
- Lossy
- Lossless
Lossy Data Compression
Lossy data compression is named for what it does. After one applies lossy data compression a message, the message can never be recovered exactly as it was before it was compressed. When the compressed message is decoded it does not give back the original message. Data has been lost. Because lossy compression cannot be decoded to yield the exact original message, it is not a good method of compression for critical data, such as textual data. It is most useful for digitally sampled analog data (DSAD). DSAD consists mostly of sound, video, graphics, or picture files. Algorithms for lossy compression of DSAD vary, but many use a threshold level truncation. This means that a level is chosen past which all data is truncated. In a sound file, for example, the very high and low frequencies, which the human ear cannot hear, maybe truncated from the file.
Generally, lossy data compress will be guided by research on how people perceive the data in question. For example, the human eye is more sensitive to subtle variations in luminance than it is to variations in color. JPEG image compression works in part by “rounding off” some of this less-important information. Lossy data compress provides a way to obtain the best fidelity for a given amount of compression. In some cases, transparent (unnoticeable) compression is desired; in other cases, fidelity is sacrificed to reduce the amount of data as much as possible. Some examples of lossy data compression algorithms are JPEG, MPEG, and Indeo.
Lossless Data Compression
The Lossless compression algorithms usually exploit statistical redundancy in such a way as to represent the sender’s data more concisely without error. Lossless data compress is possible because most real-world data has statistical redundancy. For example. in English text. the letter ‘e‘ is much more common than the letter ‘z’ and the probability that the letter ‘q’ will be followed by the letter ‘z’ is very small.
In a lossless data compress file, the original message can he exactly decoded. Lossless data compression works by finding repeated patterns in a message and encoding those patterns in an efficient manner. For this reason, lossless data compression is also referred to as redundancy reduction. Because redundancy reduction is dependent on patterns in the message. it does not work well on random messages. Lossless data compression is ideal for text. Most of the algorithms for lossless compression are based on the LZ compression method developed by Lempel and Ziv.
Lossless Versus Lossy Compression
- Lossless compress schemes are reversible so that the original data can be reconstructed. while lossy schemes accept some loss of data in order to achieve higher compression.
- However, lossless data compression algorithms will always fail to compress some files: indeed, any compression algorithm will necessarily fail to compress any data containing no discernible patterns. Attempts to compress data that has been compressed already will therefore usually result in an expansion, as will attempts to compress encrypted data.
- In practice, lossy data compress will also come to a point where compressing again does not work, although an extremely lossy algorithm, which for example always removes the last byte of a file, will always compress a file up to the point where it is empty.
An example of lossless vs. lossy compression is the following string:
25.888888888
This string can be compressed as:
25. [9] 8
Interpreted as, “twenty five-point 9 eights”, the original string is perfectly recreated, just written in a smaller form.
In a lossy system, using 26 instead, the original data is lost, at the benefit of smaller file size.
Advantages and Disadvantages
- Compression is useful because it helps reduce the consumption of expensive resources. such as hard disk space.
- Compression is also useful because it helps to reduce the transmission bandwidth (computing).
- On the downside, compressed data must be decompressed to be used. this extra processing may be detrimental to some applications.
- For instance, a compression scheme for video may require expensive hardware for the video to be decompressed fast enough to be viewed as its being decompressed. The option of decompressing the video in full before watching it may be inconvenient and requires storage space for the decompressed video.
- The design of these schemes, therefore, involves trade-offs among various factors. including the degree of compression. The amount of distortion introduced (for the lossy scheme), and the computational resources required to compress and uncompress the data.